정규식(Regular Expression) 함수
SQL 문장에서도 유닉스에서 사용하는 정규식을 사용해 다양한 검색을 할 수 있다. 정규식은 다양한 메타 문자들을 사용해 검색방법을 확장한것. 유닉스 버전마다 조금씩 다를 수 있지만 주로 사용하는 정규식 방법은 아래와 같다
정규 표현식 |
||
^ (캐럿) |
해당 문자로 시작하는 line 출력 |
‘^pattern’ |
$ (달러) |
해당 문자로 끝나는 line 출력 |
‘pattern$’ |
. |
S로 시작하여 E으로 끝나는 line ( . =1 character) |
‘S . . . .E ’ |
* |
모든 이라는 뜻, 글자수가 0 일수도 있음 |
‘[a–z]*’ |
[ ] |
해당 문자에 해당하는 한 문자 |
‘[Pp]attern’ |
[ ^ ] |
해당 문자에 해당하지 않는 한 문자 |
‘[^a–m]attern’ |
[:문자클래스:] : alpha, blank, cntrl, digit, graph, lower, print, space, uppper, xdigit
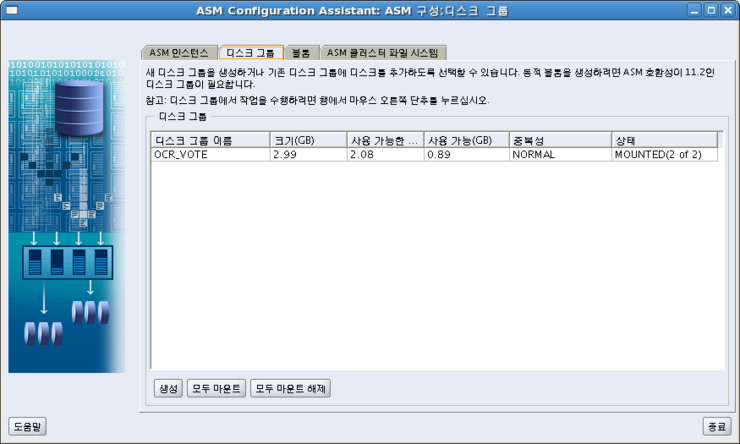
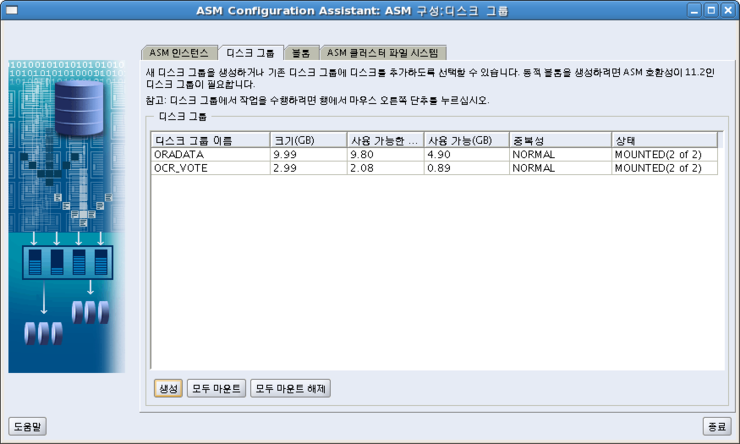
연습용 테이블 확인
SCOTT>SELECT * FROM t_reg; TEXT ---------- ABC123 ABC 123 ABC 123 abc 123 abc 123 a1b2c3 aabbcc123 ?/!@#$*& \~*()., 123123 123abc abc
1. REGEXP_LIKE 함수
like 함수처럼 특정 패턴과 매칭되는 결과를 검색
사용예
영문자가 들어가 있는 행만 출력하기
- 소문자, 대문자, 대소문자가 들어가있는 행을 출력하는 예
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '[a-z]');
TEXT ---------- abc 123 abc 123 a1b2c3 aabbcc123 123abc abc
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '[A-Z]'); // '[[:upper:]]' 와 같은결과
TEXT ---------- ABC123 ABC 123 ABC 123
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '[a-zA-Z]');
TEXT ---------- ABC123 ABC 123 ABC 123 abc 123 abc 123 a1b2c3 aabbcc123 123abc abc
영문자로 시작하고 공백을 포함하는 경우
- 소문자로 시작, 뒤에 공백이 있는 경우
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '[a-z] '); //소문자로 시작, 뒤에 공백이 있는 모든 행을 출력
TEXT ---------- abc 123 abc 123
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '[a-z] [0-9]'); //소문자로 시작, 공백이 1칸있고 숫자로 끝나는 모든 행을 출력
TEXT ---------- abc 123
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '[[:space:]]'); //공백이 있는 데이터를 모두 출력
TEXT ---------- ABC 123 ABC 123 abc 123 abc 123
연속적인 글자 수 지정하기
대문자가 연속적으로 2글자 이상 오는 경우 출력
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '[A-Z]{2}');
TEXT ---------- ABC123 ABC 123 ABC 123영어대문자 다음에 숫자가 함께 오는데 영어대문자와 숫자가 각각 3글자 오는 행 출력
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '[A-Z][0-9]{3}');
TEXT -------- ABC123
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '[0-9][A-Z]{3}'); no rows selected
특정 위치를 지정하여 출력
- 시작되는 문자 지정 : ^(캐럿) cf.대괄호 안에 있는 캐럿은 NOT의 의미.
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '^[A-Za-z]'); // 대문자나 소문자로 시작하는 행 출력
TEXT ---------- ABC123 ABC 123 ABC 123 abc 123 abc 123 a1b2c3 aabbcc123 abc
SCOTT>SELECT * FROM treg 2 WHERE REGEXP_LIKE(text, '^[0-9A-Z]'); // 숫자나 대문자로 시작하는 행 출력
TEXT ---------- ABC123 ABC 123 ABC 123 123123 123abc
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '^[a-z]|^[0-9]'); // 소문자나 숫자로 시작하는 행 출력 (여러조건을 줄때 바(|) 기호사용해 연결가능)
TEXT ---------- abc 123 abc 123 a1b2c3 aabbcc123 123123 123abc abc 끝나는 문자 지정 : $(달러)
SCOTT>SELECT name, id 2 FROM student 3 WHERE REGEXP_LIKE(id, '^M(a|o)'); // M으로 시작하고 두번째가 a나 o가 나오는 id 출력
NAME ID ------------------------------ -------------------- Demi Moore Moore Steve Martin Martin
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '[a-zA-Z]$'); // 소문자나 대문자로 끝나는 행 출력 , = '[[:alpha:]]$'
TEXT ---------- 123abc abc
대괄호안에 있는 ^(캐럿): NOT의 의미.
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '^[^a-z]'); // 소문자로 시작하지 않는 행을 출력
TEXT ---------- ABC123 ABC 123 ABC 123 ?/!@#$*& \~*()., 123123 123abc
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '^[^0-9a-z]'); // 숫자나 소문자로 시작하지 않는 행 출력
TEXT ---------- ABC123 ABC 123 ABC 123 ?/!@#$*& \~*().,
SCOTT>SELECT * FROM t_reg 2 WHERE REGEXP_LIKE(text, '[^a-z]'); //위치와 상관없이 소문자만 들어 있는 행을 제외하고 모두 출력
TEXT ---------- ABC123 ABC 123 ABC 123 abc 123 abc 123 a1b2c3 aabbcc123 ?/!@#$*& \~*()., 123123 123abc //t_reg 테이블의 맨 아랫줄 abc 행이 제외됨.
SCOTT>SELECT * FROM t_reg 2 WHERE NOT REGEXP_LIKE(text, '[a-z]'); // 소문자가 들어간 모든 행을 제거하고 모두 출력
TEXT ---------- ABC123 ABC 123 ABC 123 ?/!@#$*& \~*()., 123123다른여러 예들.
SCOTT>SELECT name, tel 2 FROM student 3 WHERE REGEXP_LIKE(tel, '^[0-9]{2}\)[0-9]{4}'); //지역번호가 2자리고 국번이 4자리가 나오는값 출력
NAME TEL ----------------------------- --------------- Demi Moore 02)6255-9875 Richard Dreyfus 02)6788-4861 Steve Martin 02)6175-3945 Anthony Hopkins 02)6122-2345
SCOTT>SELECT name, id 2 FROM student 3 WHERE REGEXP_LIKE(id, '^...r..'); // 넷째 자리에 r이 있는 행을 출력
NAME ID ------------------------------ -------------------- James Seo 75true Bill Murray Murray
SCOTT>SELECT * FROM t_reg2 2 WHERE REGEXP_LIKE(ip, '^[172]{3}\.[16]{2}\.[168]{3}'); // 아래의 결과와 같이 대괄호 안의 숫자의 순서와는 상관없이 해당 숫자가 있는 행은 모두 출력됨.
NO IP ---------- -------------------- 4 172.61.186.2 5 172.61.168.2
특정 조건을 제외한 결과 출력하기
- ex) 영문자(대소문자)를 포함하지 않는 모든행 출력
SCOTT>SELECT * FROM t_reg 2 WHERE NOT REGEXP_LIKE(text, '[a-zA-Z]');
TEXT ---------- ?/!@#$& \~()., 123123
특수문자 찾기 : ? 나 * 이 포함된 행을 출력할경우 탈출문자(\)를 사용하면됨.
2. REGEXP_REPLACE 함수
Replace 함수를 확장한 개념으로 주어진 문자열에서 특정 패턴을 찾아서 주어진 다른 형태로 치환하는 함수.
문법: REGEXP_REPLACE(source_char, pattern
[, replace_string
[, position
[, occurrence
[, match_param]]]]
)
- -c: 대소문자 구분해서 검색
- -i : 대소문자 구분않고 검색
- -m : 검색조건을 여러줄로 줌.
사용예
- ex1) 예제 테이블 t_reg에서 숫자부분을 '*' 기호로 전부 변경
SCOTT>SELECT text, REGEXP_REPLACE(text, '[[:digit:]]', '*') "NO -> CHAR" 2 FROM t_reg;
TEXT NO -> CHAR ---------- -------------------- ABC123 ABC*** ABC 123 ABC *** ABC 123 ABC *** abc 123 abc *** abc 123 abc *** a1b2c3 a*b*c* aabbcc123 aabbcc*** ?/!@#$*& ?/!@#$*& \~*()., \~*()., 123123 ****** 123abc ***abc abc abc
- ex2) 특정 패턴 찾아서 변경하기
SCOTT>SELECT text, 2 REGEXP_REPLACE(text, '([0-9])', '\1-*') "Add Char" //숫자뒤에 -* 붙이기 3 FROM t_reg;
TEXT Add Char ---------- ------------------------------ ABC123 ABC1-*2-*3-* ABC 123 ABC 1-*2-*3-* ABC 123 ABC 1-*2-*3-* abc 123 abc 1-*2-*3-* abc 123 abc 1-*2-*3-* a1b2c3 a1-*b2-*c3-* aabbcc123 aabbcc1-*2-*3-* ?/!@#$*& ?/!@#$*& \~*()., \~*()., 123123 1-*2-*3-*1-*2-*3-* 123abc 1-*2-*3-*abc abc abc
SCOTT>SELECT text, 2 REGEXP_REPLACE(text, '([0-9])', '-*') "Add Char" 3 FROM t_reg;
TEXT Add Char ---------- ------------------------------ ABC123 ABC-*-*-* ABC 123 ABC -*-*-* ABC 123 ABC -*-*-* abc 123 abc -*-*-* abc 123 abc -*-*-* a1b2c3 a-*b-*c-* aabbcc123 aabbcc-*-*-* ?/!@#$*& ?/!@#$*& \~*()., \~*()., 123123 -*-*-*-*-*-* 123abc -*-*-*abc abc abc 12 rows selected.
SCOTT>SELECT no, ip, 2 REGEXP_REPLACE(ip, '\.', '') "Dot Remove" 3 FROM t_reg2;
NO IP Dot Remove ---- -------------------- -------------------- 1 10.10.0.1 101001 2 10.10.10.1 1010101 3 172.16.5.100 172165100 4 172.61.186.2 172611862 5 172.61.168.2 172611682 6 255.255.255.0 2552552550 6 rows selected.
SCOTT>SELECT no, ip, 2 REGEXP_REPLACE(ip, '\.', '/', 1,1) "REPLACE" 3 FROM t_reg2;
NO IP REPLACE ---- -------------------- -------------------- 1 10.10.0.1 10/10.0.1 2 10.10.10.1 10/10.10.1 3 172.16.5.100 172/16.5.100 4 172.61.186.2 172/61.186.2 5 172.61.168.2 172/61.168.2 6 255.255.255.0 255/255.255.0
- 사용자에게 입력받은 문자중 공백이 여러개 포함돼있을 경우 그 공백을 제거시키는 방법
SCOTT>SELECT REGEXP_REPLACE('aaa bbb', '( ){1,}','')
2 FROM dual;
REGEXP
------
aaabbb
위의 예제에서 {1,}부분을 {1}로 해도됨. { }내의 숫자는 앞문자가 나타나는 횟수 또는 범위를 의미함.
ex) a{5} = 'a'의 5번 반복한 aaaaa 만을 의미
ex) a{3,} = aaa, aaaa, aaaaa, .....
ex) a{3,5} = aaa, aaaa, aaaaa
ex) ab{2,3} = abb, abbb
- 'abc bbb'에서 공백이 두칸이상 인 것만 공백을 제거해 출력
SCOTT>SELECT REGEXP_REPLACE('aaa bbb', '( ){1,}','')
2 FROM dual;
REGEXP
------
aaabbb
SCOTT>SELECT REGEXP_REPLACE('aaa bbb', '( ){2,}', '') "ONE",
2 REGEXP_REPLACE('aaa bbb', '( ){2,}', '') "Two"
3 FROM dual;
ONE Two
------- ------
aaa bbb aaabbb
SCOTT>SELECT REGEXP_REPLACE('aaa bbb', '( ){2,}', '*') "ONE",
2 REGEXP_REPLACE('aaa bbb', '( ){2,}', '*') "Two",
3 REGEXP_REPLACE('aaa bbb', '( ){2,}', '*') "Three"
4 FROM dual;
ONE Two Three
------- ------- -------
aaa bbb aaa*bbb aaa*bbb
- 사용자가 입력한 단어에 공백 문자가 처음에 포함돼있고 중간에도 공백이 포함되어 있다고 가정하고 그 단어에서 모든 공백을 제거한 후 조회하는 예제.
SCOTT>SELECT studno, name, id
2 FROM student
3 WHERE id = REGEXP_REPLACE('&id', '( ){1,}', '');
Enter value for id: 75 true
STUDNO NAME ID
---------- ------------------------------ --------------------
9411 James Seo 75true
SCOTT>SELECT studno, name, id
2 FROM student
3 WHERE id = LOWER(REGEXP_REPLACE('&id', '( ){1,}', '')); /소문자화
Enter value for id: 75 TRUE
STUDNO NAME ID
---------- ------------------------------ --------------------
9411 James Seo 75true
- 특정 문자열의 형태를 다른 형태로 바꿀 때
SCOTT>SELECT REGEXP_REPLACE('20160905',
2 '([[:digit:]]{4})([[:digit:]]{2})([[:digit:]]{2})',
3 '\1-\2-\3')
4 FROM dual;
REGEXP_REP
----------
2016-09-05
3. REGEXP_SUBSTR 함수
SUBSTR 함수의 확장판. 특정 패턴에서 주어진 문자를 추출해 내는 함수.
사용예
- 교수테이블(professor)테이블에서 홈페이지(hpage) 주소가 있는 교수들만 조사해서 아래의 화면처럼 나오게 출력하시오.
SCOTT>SELECT name, LTRIM(REGEXP_SUBSTR(hpage, '/([[:alnum:]]+\.?){3,4}?'), '/') "URL"
2 FROM professor
3 WHERE hpage IS NOT NULL ;
NAME URL
-------------------- --------------------
Audie Murphy www.abc.net
Angela Bassett www.abc.net
Jessica Lange www.power.com
Michelle Pfeiffer num1.naver.com
hpage 컬럼을 조회하여 ‘http://’ 부분을 제거하고 . 으로 구분되는 필드를 최소 3개에서 최대 4개까지 출력하라는 의미. 그 후에 왼쪽부분에 나오는 ‘/ ’ 기호를 LTRIM 함수로 제거함.
- Professor 테이블에서 101번 학과와 201번 학과 교수들의 이름과 메일 주소의 도메인 주소를 출력하시오. 단 메일 주소는 @뒤에 있는 주소만 출력하시오.
SCOTT>SELECT name, LTRIM(REGEXP_SUBSTR(email, '@([[:alnum:]]+\.?){3,4}?'), '@') domain
2 FROM professor
3 WHERE deptno IN (101,201) ;
NAME DOMAIN
-------------------- --------------------
Audie Murphy abc.net
Angela Bassett abc.net
Jessica Lange power.com
Meryl Streep daum.net
Susan Sarandon def.com
- 특정기호나 문자를 기준으로 데이터를 추출할 때
SCOTT>SELECT REGEXP_SUBSTR('sys/oracle@racdb:1521:racdb',
2 '[^:]+', 1, 3) result // : 기호를 기준으로 3번재의 문자열을 추출
3 FROM dual;
RESULT
----------
racdb
SCOTT>SELECT REGEXP_SUBSTR('sys/oracle@racdb:1521:racdb',
2 '[^/:]+', 1, 2) result // 슬래쉬를 기준으로 출력
3 FROM dual;
RESULT
--------------
oracle@racdb
4. REGEXP_COUNT 함수
특정 문자의 개수를 세는 함수
사용예
- 주어진 문자열에서 대문자 'A'가 몇개인지 찾아 주는 예
SCOTT>SELECT text, REGEXP_COUNT(text, 'A') 2 FROM t_reg;
TEXT REGEXP_COUNT(TEXT,'A') ---------- ---------------------- ABC123 1 ABC 123 1 ABC 123 1 abc 123 0 abc 123 0 a1b2c3 0 aabbcc123 0
- 검색 위치를 3으로 지정해서 3번째 문자 이후부터 해당 소문자 ‘c’ 가 나오는 개수를 세는 예
SCOTT>SELECT text, REGEXP_COUNT(text, 'c', 3) 2 FROM t_reg;
TEXT REGEXP_COUNT(TEXT,'C',3) ---------- ------------------------ ABC123 0 ABC 123 0 ABC 123 0 abc 123 1 abc 123 1 a1b2c3 1 aabbcc123 2 ?/!@#$*& 0 \~*()., 0 123123 0 123abc 1 abc 1
SCOTT>SELECT text, REGEXP_COUNT(text, 'c') "RESULT 1", 2 REGEXP_COUNT(text, 'c', 1, 'i') "RESULT 2" //대소문자 구분 없이 (즉 'C' 와 'c' 모두) 몇 개가 나오는 지 세어 출력 3 FROM t_reg;
TEXT RESULT 1 RESULT 2 ---------- ---------- ---------- ABC123 0 1 ABC 123 0 1 ABC 123 0 1 abc 123 1 1 abc 123 1 1 a1b2c3 1 1 aabbcc123 2 2 ?/!@#$*& 0 0 \~*()., 0 0 123123 0 0 123abc 1 1 abc 1 1
SCOTT>SELECT text, 2 REGEXP_COUNT(text, 'aa') RESULT1, 3 REGEXP_COUNT(text, 'a{2}') RESULT2, 4 REGEXP_COUNT(text, '(a)(a)') RESULT3 5 FROM t_reg;
TEXT RESULT1 RESULT2 RESULT3 ---------- ---------- ---------- ---------- ABC123 0 0 0 ABC 123 0 0 0 ABC 123 0 0 0 abc 123 0 0 0 abc 123 0 0 0 a1b2c3 0 0 0 aabbcc123 1 1 1 ?/!@#$*& 0 0 0 \~*()., 0 0 0 123123 0 0 0 123abc 0 0 0 abc 0 0 0
[출처] 다양한 예제로 쉽게 배우는 오라클 SQL과 PL/SQL 서진수 저
'Oracle > sql' 카테고리의 다른 글
| [SQL] 4. JOIN (796) | 2016.09.12 |
|---|---|
| [SQL] 3. 복수행함수(그룹함수) (153) | 2016.09.05 |
| [SQL] 2. 단일행함수(일반함수) (11) | 2016.09.02 |
| [SQL] 2. 단일행함수(숫자, 날짜, 형변환 함수) (993) | 2016.08.30 |
| [SQL] 2. 단일행함수(문자함수) (7) | 2016.08.29 |